Hello nerds.
Today we will be exploring my Spotify library with some data analytics.
I got this idea as I was trying to figure out a way to get artist information from your Spotify for another idea that I had, when I came across this site, https://exportify.net/. Using this site, anyone can log in to their Spotify account, and export playlists as a .csv file. The author of this site, Pavel Komarov, then set up a fancy dancy webpage (Jupyter notebook) where one can upload their exported playlist and do some neat analysis on it. So what I have done is added all of my liked songs (total of 6,195) into a separate playlist titled “TheCollection” and then exported it using exportify, uploaded it to the notebook, and followed his code, with some slight modifications, to produce some cool graphs. Most of the heavy lifting is done for you already so if you yourself are curious about your own musical tastes, the process shouldn’t be that hard to replicate, the only thing you would need to do is upload your own playlist!
Along the way I take two tangents and take a look behind the curtains of Spotify to see how some of the data that is analyzed is collected and what exactly they do with this data.
Let’s dive in.
First up is songs per artist.

You can see that a large proportion of my library is artists for whom I’ve only liked one or two songs. I think this reflects how I often listen to music, being more explorative of different genres and artists and rarely immersing myself in a complete discography. However, there are a handful of artists for which it seems like I’ve liked their entire collection. I had no trouble guessing the top two artists with the most liked songs, however I was surprised with some others, mainly Kanye West and Kendrick Lamar.
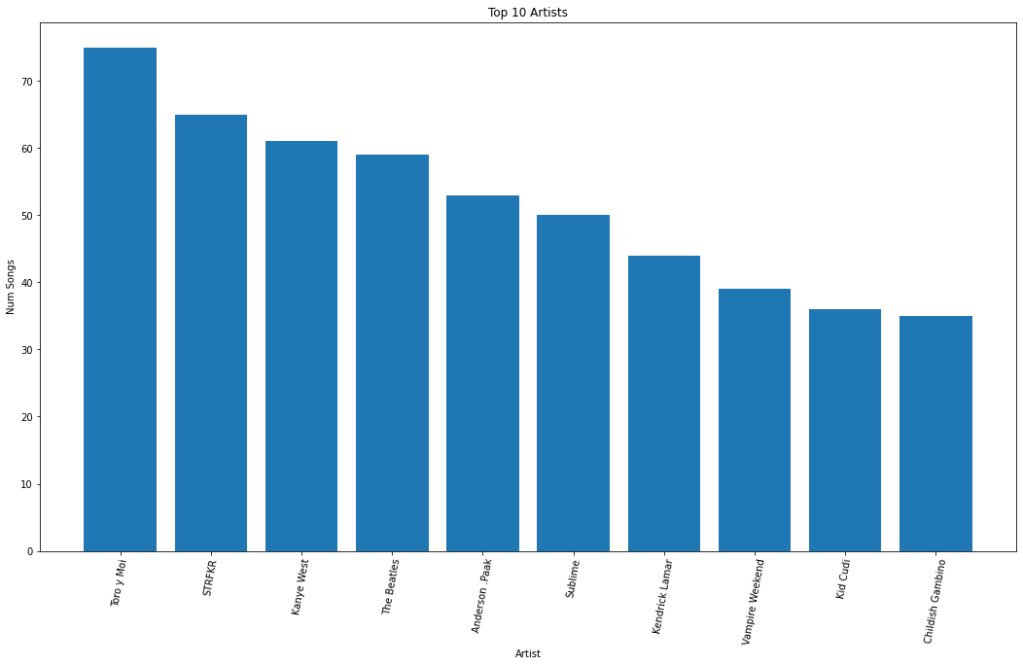
This graph really highlights those handful of artists that I’ve spent a good month or two really listening to their complete collection. Back in the early days of my Spotify, I went into a deep dive of Sublime’s discography (as every 20 something college kid does) and was liking virtually every song from their albums. Nowadays, I rarely listen to Sublime, but still enjoy a one off song here and there. The Beatles is the same scenario, in the early days of the pandemic (April 2020) I listened to all 13 of their albums all the way through. Naturally, my Top Songs of 2020 also had around 15 Beatles songs. Kanye West and Kendrick Lamar are a different story, I never did a deep dive for these artists as I did with the others so I am surprised with how many songs of theirs I have in my library. My only possible explanation is that they are frequent collaborators on a ton of other artist’s songs, suggesting I am more of a fan of mainstream rap/hip-hop than Kanye and Kendrick specifically. I would still listen and enjoy these artists (Sublime, The Beatles, Kanye West, Kendrick Lamar), but I wouldn’t say they are within my top 10 favorite artists. Something which I am able to say for the likes of Toro y Moi, STRFKR, Vampire Weekend, and Childish Gambino. Lets expand the ranking to see if who I think are my favorite artists make an appearance.
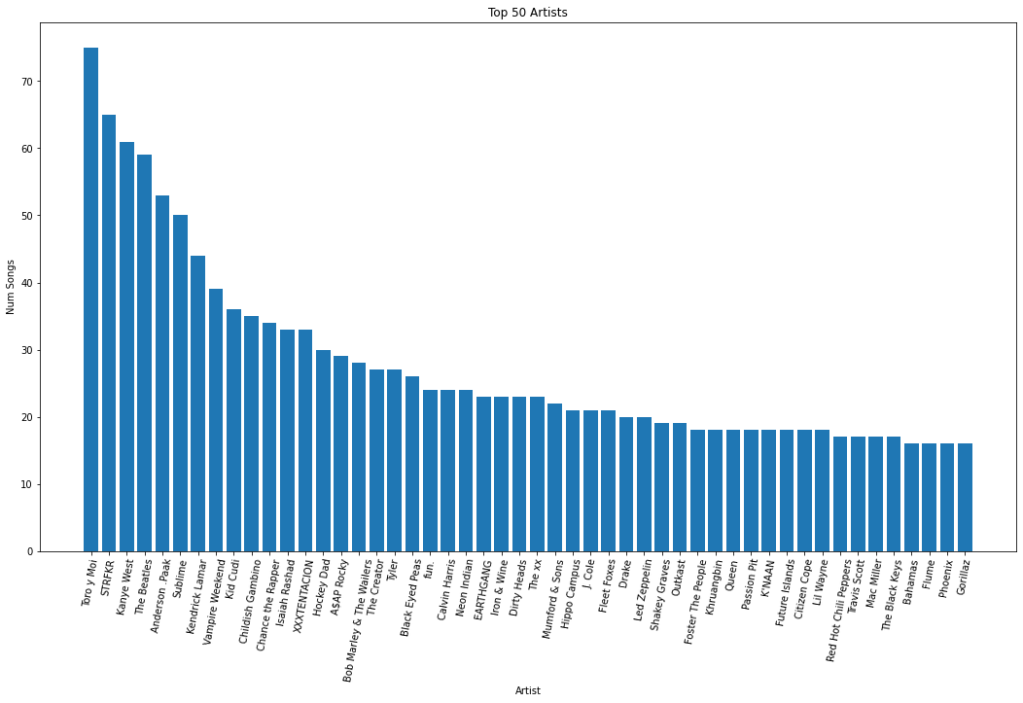
Looks like some of my favorite artists just miss the top 10 (Chance the Rapper, Isaiah Rashad, Hockey Dad) while some others are further down the line (Neon Indian, Fleet Foxes, Future Islands). Again some surprises (ASAP Rocky, Calvin Harris, Black Eyed Peas) and some humorous glimpses into my past musical taste (I had a weird fun. obsession in high school).
Now onto the genres and our first tangent of the day. If you use Spotify, you must have wondered at some point what the hell are all those weird genres and why are there so many of them on Spotify? Well it turns out that a culprit responsible for this madness can be singled out and his name is Glenn McDonald.
/https://www.thestar.com/content/dam/thestar/entertainment/2016/01/14/meet-the-man-classifying-every-genre-of-music-on-spotify-all-1387-of-them/glennmcdonald.jpg)
Glenn is an employee at Echo Nest (something you will learn about later, but briefly it’s what powers everything that Spotify does) and his job is to basically create genres of music.
Not in reality, but he does get to name new genres whatever he wants which makes for some funny reading. What Spotify actually does, again more information later on in the post, is they keep track of certain features for every song in it’s database. These features are music related (i.e. tempo), but also include other things such as where in the world the artist is from and the context to which that song was listened to (what was played before it, time of day it was played, etc.). All this information is combined and using some high level computer science and math, tracks and artists are attempted to be put into clusters based off of their similarity to one another.
It is from this clustering that Spotify genres are born. When a group of songs or artists start to form a recognizable and independent cluster away from others, they can be technically called their own genre. This is where Glenn comes in with his naming. His job is to listen to the music and come up with an appropriate name for that genre. A genre that appears in my collection, “Escape Room” can be described as artists who feel “connected to trap sonically,” but are more related to “experimental-indie-r&b-pop” than they are to traditional trap. Glenn says “it just sort of felt like it was solving and creating puzzles.”. Right on Glenn.
So now that we know how genres are formed and why there are so many of them (5,507 as of today), I want to introduce you to Glenn’s little side project, a website that attempts to show all genres in a 2-D scatter plot of the genre space. Take a look:
https://everynoise.com/engenremap.html
The site is pretty cool. It is generally organized as those things closer to the top being more mechanical, down is more organic, left is denser and more atmospheric, right is spikier and bouncier. You can click on any genre to hear an example track that represents that genre as well as click the arrows to the right of any genre to see a map of the artists that fall into that genre. If you were ever curios what the genre of fussball (which just seems to be songs and artists singing about German football) looks like here it is:
As you can see, you can click on the buttons at the top to be taken to a variety of playlists for that genre, playlist being the master playlist for that genre, intro being a shorter playlist, pulse being what fans of that genre are currently rotating, 2020 and new being pretty self explanatory.
The site also has a lot more to offer. If you click on the other things button at the top you will be brought to a list of various off shoots of the website. If you’re bored you can spend a good couple hours exploring but here are a few of my highlights:
Every Place at Once: thousands of playlists for individual cities that are filled with songs that distinguish that city from every other city. An example for Bellingham:
Every School at Once: same idea but for universities around the world. WWU’s playlist:
The Needle: This machine basically attempts to find songs that are “rising from the depths of obscurity”. Its divided into three playlists based on the depth the machine attempts to find songs. Current is the shallowest search, while underground is the most extensive and obscure.
Back to the graphs
Turns out I have 1147 unique genres within my collection, representing 20.82 % of Spotify’s genres. Similar to my artists, there is a large proportion of genres with only one or two songs and a handful of genres with multiple hundred songs.
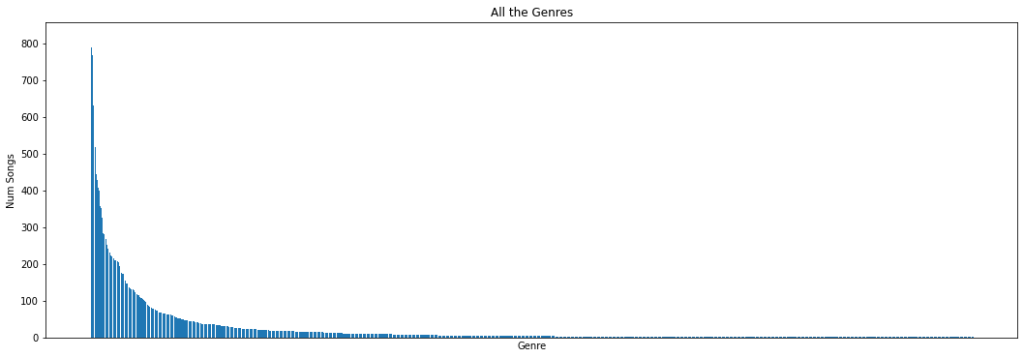
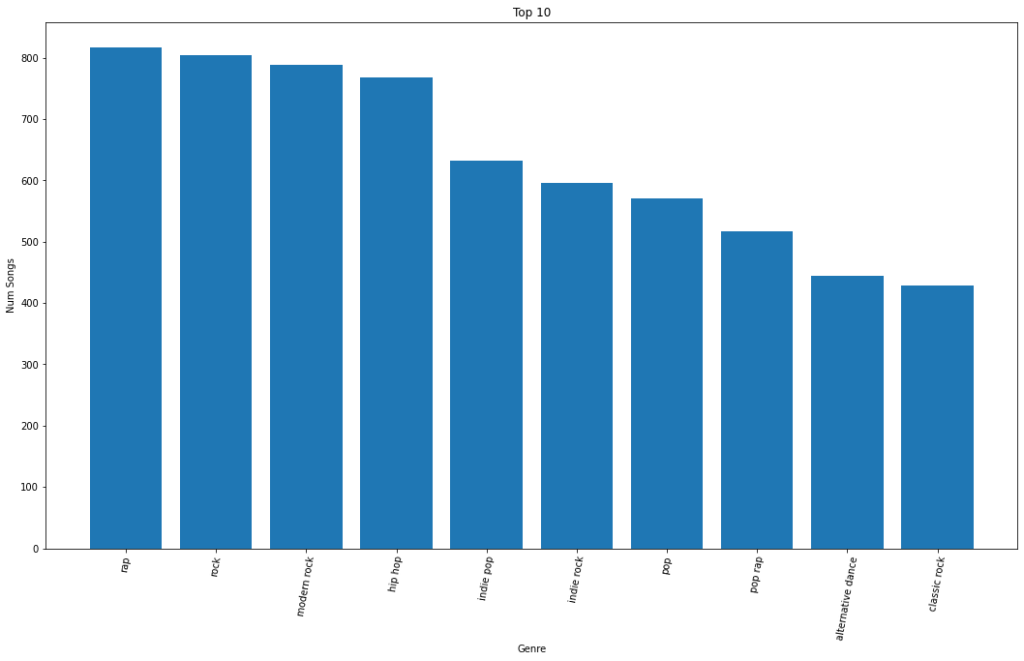
Not really surprised by my top ten genres, seems pretty cut and dry.
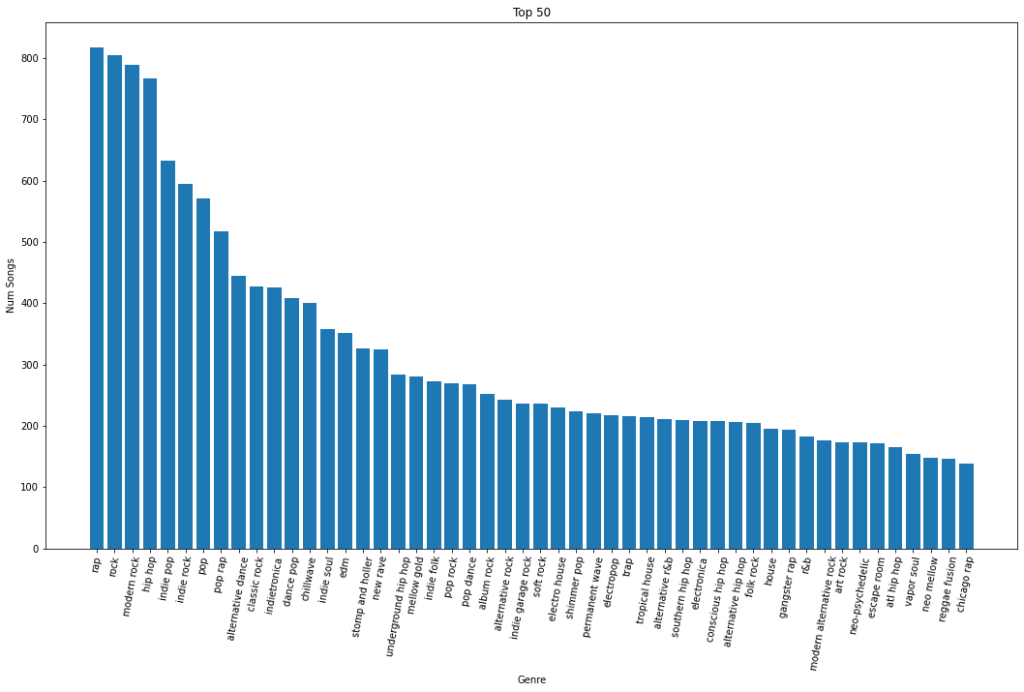
Some more obscure genres start to pop up when we look at the top 50. Some of those being “mellow gold”, “escape room” and “vapor soul”. Maybe there are some strange ones down at the bottom.

Definitely some unique names.
Looking at what songs these actually are:
| Song – Artist Genres: |
| Collarbone – Fujiya & Miyagi Genres: alternative dance, brighton indie, electronica, neo-kraut, new rave |
| Feelin’ It (Salva Remix) – Umii,Salva Genres: portland indie, glitch hop, purple sound |
| Electric Pow Wow Drum – The Halluci Nation Genres: canadian indigenous, canadian indigenous hip hop, escape room, ottawa rap |
| Surrender – Josh White Genres: christian uplift |
| Les Champs-Elys̩es РJoe Dassin Genres: chanson, chanson paillarde, french pop |
| Make It Wit Chu – Queens of the Stone Age Genres: alternative metal,alternative rock,blues rock,modern rock,nu metal,palm desert scene,rock,stoner metal,stoner rock |
| Bad (feat. Vassy) – Radio Edit – David Guetta,Showtek,VASSY Genres: big room, dance pop, edm, pop, pop dance, classic hardstyle, electro house, euphoric hardstyle, progressive electro house, progressive house, australian dance |
| Switzerland – The Last Bison Genres: hampton roads indie, stomp and holler |
| Old Love – Joe Hertler & The Rainbow Seekers Genres: michigan indie |
| Okan Bale – Angelique Kidjo Genres: afropop, beninese pop, world |
| Varúð – Sigur Rós Genres: bow pop, dream pop, ethereal wave, icelandic rock, melancholia, nordic post-rock, post-rock |
| Calabria 2007 (feat. Natasja) – Enur,Natasja Genres: reggae fusion,classic danish pop, danish hip hop, danish pop |
As I mentioned earlier, Spotify’s algorithms creates genres based off where that artist is from (hampton roads indie, michigan indie, beninese pop, danish hip hop) which is kind of disappointing. I would agree that this makes sense for larger geographical regions (i.e, nordic post rock, australian dance) or for certain genres such as rap and hip hop where where you’re from does have a large say in the style (southern hip hop, chicago rap). However narrowing it down to a city like Brighton just seems strange. I doubt every indie band from Brighton has the exact same sound.
Spotify also has a Popularity value that it assigns to every single song, ranging from 0 to 100, with 100 being most popular. My library has a pretty normal distribution of popularity values if you ignore the large number of songs with 0 popularity. I took a closer look at some songs with 0 popularity and I believe some of them have been misclassified or simply haven’t had an appropriate value assigned to them yet showing errors within Spotify’s framework. There are some Drake songs with 0 popularity which just doesn’t make sense.
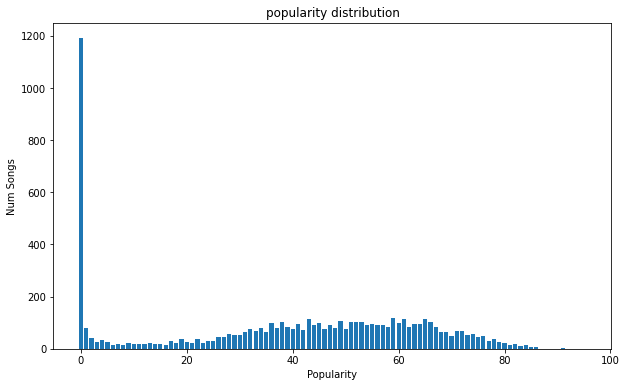
The popularity rating also seems to have a bias for songs that are popular right now, meaning that #1 hits from decades ago will most likely have a popularity rating around ~50 which I guess makes sense. Taking a look at my top ten most popular songs confirms this.
| Track Name Artist Name(s) | Popularity |
| Leave The Door Open Bruno Mars, Anderson .Paak, Silk Sonic | 95 |
| Blinding Lights The Weeknd | 94 |
| telepatía Kali Uchis | 92 |
| Save Your Tears The Weeknd | 91 |
| Rasputin Majestic, Boney M. | 91 |
| BED Joel Corry, RAYE, David Guetta | 90 |
| Head & Heart (feat. MNEK) Joel Corry, MNEK | 89 |
| Circles Post Malone | 88 |
| bad guy Billie Eilish | 87 |
| Dance Monkey Tones And I | 86 |
In order to analyze the rest of the metrics that Spotify tracks and the algorithms it uses, a little history lesson is needed.
The story starts in 2005 with the doctoral dissertations of two graduate students in the Media Arts and Science department at MIT, Tristan Jehan and Brian Whitman.


These two, as I think they should forever be referenced as, gods of music discovery shared a deep interest in combining science and music during their graduate studies. In general terms, they were both attempting to break down and simplify an extremely complex language, music, into something a computer could understand and utilize.
Specifically, Tristan was interested in building tools for audio analysis, with the end goal being using these tools to create a computer that was capable of synthesizing novel pieces of music. Immediately, my mind jumped to a scenario where you come home from work, take off your shoes, pour yourself a stiff one and your robot sitting on your kitchen counter crafts up and plays you the modern day equivalent of Fur Elise while you heat up some frozen chicken nuggets in the microwave. As Tristan put it in his thesis, “Our goal is more specifically to build a machine that defines its own creative rules, by listening to and learning from musical examples.”. I am no computer science expert (side note: all theses should include a section that is limited on technical jargon and is written for the general population explaining what the thesis is about), but it is my understanding that the system Tristan built takes a ginormous database of songs, uses the tools that Tristan created to analyze each song and learn what makes a song a song, and then chops up various songs and puts it together in a novel fashion. For an example of this technology in action, visit his personal website and click on audio example:
https://web.media.mit.edu/~tristan/
However, the real goldmine wasn’t this computer that was capable of stitching together various bits and pieces of music, it was the tools the computer used to learn about music. Tristan realized that the tools could be used to make music more personal by understanding on a deeper level why a certain song is enjoyed by a certain person.
This particular paragraph from his thesis explaining the motivation behind his research points to this realization.
“The motivation behind this work is to personalize the music experience by seamlessly merging together listening, composing, and performing. Recorded music is a relatively recent technology, which already has found a successor: synthesized music, in a sense, will enable a more intimate listening experience by
potentially providing the listeners with precisely the music they want, whenever they want it. Through this process, it is potentially possible for our “metacomposer” to turn listeners—who induce the music—into composers themselves. Music will flow and be live again. The machine will have the capability of monitoring and improving its prediction continually, and of working in communion with millions of other connected music fans.”
It is no wonder why this guy made it with that kind of entrepreneurial thinking.
It is important to note that the “deeper level of understanding” is key here. It turns out that it is quite easy for a computer to listen to a song and extract information such as tempo, pitch and loudness. This is what Tristan and Brian call low level information. What really sets Tristan’s audio analysis tools apart, is that it combines this low level information using machine learning (taking a huge set of data and telling the computer to separate data into appropriate classifications, repeat using information learned about the accuracy of the first go, see above) to create high level information about songs such as danceability, acousticness, valence (mood). These metrics can more accurately describe a song compared to low level information such as tempo. For example, just because two songs have a medium-high tempo, does not necessarily mean they are both danceable.
A good example:
Lazy Eye – Silversun Pickups Tempo: 127 beats per minute
Thriller – Michael Jackson, Tempo: 127 beats per minute
Although if a song has a tempo of 127 it is typical for it to also be a song with high danceability (see three tracks below). Therefore, tempo has a large influence on the danceability rating but it is not everything. Instrumentation, key, even how the song is structured (no large stretches of downtempo and irregularity) which can be tracked with these tools also have effects on the danceability of a song.
So Tristan is the bee’s knees, but what about this Brian guy?
Well, his thesis was titled “Learning the meaning of music”. Big ask.
Much like Tristan, he was also attempting to better understand music on a deeper level. However, where their interests differs is the approach they took to understand the music. While Tristan trained a computer to listen to music to understand it, Brian trained a computer to read about music to understand it. An excerpt from his personal website explains it better than I ever could:
Can a computer really listen to music? A lot of people have promised it can over the years, but I’ve (personally) never heard a fully automated recommendation based purely on acoustic analysis that made any sense – and I’ve heard them all, from academic papers to startups to our own technology to big-company efforts. And that has a lot to do with the expectations of the listener. There are certain things computers are very good and fast at doing with music, like determining the tempo or key, or how loud it is. Then there are harder things that will get better as the science evolves, like time signature detection, beat tracking over time, transcription of a dominant melody, and instrument recognition. But even if a computer were to predict all of these features accurately, does that information really translate into a good recommendation? Usually not – and we’ve shown over the years that people’s expectation of “similar” – either in a playlist or a list of artists or songs – trends heavily towards the cultural side, something that no computer can get at simply by analyzing a signal.
This was the motivation behind Brian’s research, he believed that what people were saying about the music could tell you just as much if not more information than the information within the music itself. An interesting example of this ties back to my listening habits. Tristan’s audio analysis tools can tell you a lot about one particular song, but what about multiple songs arranged in an album, or taking it a step further an artist’s complete discography? It would be hard to pin down Toro y Moi as an artist (and any artist for that matter) with a handful of quantitative metrics. Firstly, his music can vary in sound quite dramatically, and secondly, saying he has a valence of 0.63 just doesn’t really make sense. Instead, it would be easier to pin down his music with words such as “mellow”, “groovy”, and “eclectic”. In this way you can learn more information about the music as there are often various connections and influences to other music, i.e. the culture, that will not be captured using audio analysis. So, using a lot of techniques and terms that are way over my head, he basically built a way to scour the internet for any mentions of albums, songs, artists. When any mentions are found, what is being said about the music is also picked up. This is not limited to the basic-ass generic adjectives that I used (“mellow”), but will include anything and everything that one could write about music. A funny example that kept on popping up through his thesis was:
“reminds me of my ex-girlfriend”
These terms and phrases are what Brian calls “cultural vectors”. Important to note is that when a cultural vector is written, it is picked up and given a weight score that basically says how likely it would be to use that to describe a piece of music. So for example, if I said Justin Timberlake sounds like an alley cat eating a tuna sandwich, the cultural vector “cat eating a sandwich” would (hopefully) get an extremely low weighted score because what the fuck does that sound like and who describes music like that. This is beneficial as this cultural vector is essentially useless in attempting to make connections to other pieces of music, which is really the end goal. Rather, if millions of people tweeted about how “hot” Tyler, the Creator’s new album is (tis hot), he would be associated with the term hot and connections to similar artists can be made by looking for those artists also having “hot” as one of their top cultural vectors. Each artist and track has thousands of cultural vectors which change daily as the conversation around the music changes meaning connections can change drastically as an artist evolves.
Another excerpt from his personal website that gave me hope that we are making a difference out there!
“At the time I was a member of various music mailing lists, USENET groups and frequent visitor of a new thing called “weblogs” and music news and review sites. I would read these voraciously and try to find stuff based on what people were talking about. To me, while listening to music is intensely private (almost always with headphones alone somewhere), the discovery of it is necessarily social. I figured there must be a way to take advantage of all of this conversation, all the excited people talking about music in the hopes that others can share in their discovery – and automate the process. Could a computer ‘read’ all that was going on across the internet? If just one person wrote about my music on some obscure corner of the web, then the system could know that too.”
Fuck yeah. This guy is also the bee’s knees.
So these two legends met and decided to merge their ideas and form a startup called The Echo Nest.

The Echo Nest does exactly what I have just attempted to describe, it combines Tristan’s audio analysis tools with Brian’s text mining for the culture associated with the music to generate highly personalized music recommendations. And it is the best at what it does. This is due to something that has been a mainstay in Echo Nest since day one and what Tristan and Brian call “Care and Scale”.

Scale is what it sounds like and is pretty straightforward, how big is the database from which you learn about music. If you only listened to and knew about Lady Gaga, you wouldn’t be able to accurately recommend someone Mumford and Sons. Even more importantly, if you don’t know about some small time girl with a guitar who just released a banging EP from her garage, how are you going to recommend her? Echo Nest at the time (early 2010s) was novel as it had a collection of 30 million songs that it had information for. Spotify today has an extensive database (70 million songs) that is automatically updated daily (60,000 new songs per day).
Care is what they describe as being useful for both the musician and listener and is a bit more difficult to describe. An example they provide which helps in envisioning care is to use various music discovery platforms and look at similar artists for The Beatles. Most often, the similar artists will be individual band members (John, Paul, George, Ringo) and their associated acts following the breakup of The Beatles. Is that what the listener really wants when they ask for similar artists to The Beatles? Not really, if you’re a fan of the Beatles you are most likely already going to know who John, Paul, George, and Ringo are and their various projects. Care is really where Brian’s work on the culture surrounding music comes in. Rather than using purely computer based science and mathematics to tell people who they should listen to, it really makes sense to factor in what actual humans have to say. By providing more “care” and quality assurance than any other music discovery platform, Echo Nest is able to minimize it’s “WTF count”, instances where you are in disbelief why some particular music has been recommended to you.

So fast forward ten years to the early 2010s and Echo Nest has now become the de facto leader in music discovery. It is being used by clients such as MTV, Island Def Jam Records, BBC, Warner Music Group, VEVO, Nokia, and SiriusXM. In March of 2014, Spotify splashed out 100 million dollars and bought the company outright. Today, Echo Nest and the algorithms that Tristan and Brian have developed are what makes Spotify such a great music discovery and streaming service.
Now let’s take a look at the full list of the metrics that can be tracked:
Acousticness: A confidence measure from 0.0 to 1.0 of whether the track is acoustic. 1.0 represents high confidence the track is acoustic.
Danceability: how suitable a track is for dancing based on a combination of musical elements including tempo, rhythm stability, beat strength, and overall regularity. A value of 0.0 is least danceable and 1.0 is most danceable.
Duration: duration of the track in milliseconds
Energy: a measure from 0.0 to 1.0 and represents a perceptual measure of intensity and activity. Typically, energetic tracks feel fast, loud, and noisy. For example, death metal has high energy, while a Bach prelude scores low on the scale. Perceptual features contributing to this attribute include dynamic range, perceived loudness, timbre, onset rate, and general entropy.
Instrumentalness: Predicts whether a track contains no vocals. “Ooh” and “aah” sounds are treated as instrumental in this context. Rap or spoken word tracks are clearly “vocal”. The closer the instrumentalness value is to 1.0, the greater likelihood the track contains no vocal content. Values above 0.5 are intended to represent instrumental tracks, but confidence is higher as the value approaches 1.0.
Key: The key the track is in. Integers map to pitches using standard Pitch Class notation . E.g. 0 = C, 1 = C♯/D♭, 2 = D, and so on.
Liveness: Detects the presence of an audience in the recording. Higher liveness values represent an increased probability that the track was performed live. A value above 0.8 provides strong likelihood that the track is live.
Loudness: The overall loudness of a track in decibels (dB). Loudness values are averaged across the entire track and are useful for comparing relative loudness of tracks. Loudness is the quality of a sound that is the primary psychological correlate of physical strength (amplitude). Values typical range between -60 and 0 db
Mode: Mode indicates the modality (major or minor) of a track, the type of scale from which its melodic content is derived. Major is represented by 1 and minor is 0.
Speechiness: detects the presence of spoken words in a track. The more exclusively speech-like the recording (e.g. talk show, audio book, poetry), the closer to 1.0 the attribute value. Values above 0.66 describe tracks that are probably made entirely of spoken words. Values between 0.33 and 0.66 describe tracks that may contain both music and speech, either in sections or layered, including such cases as rap music. Values below 0.33 most likely represent music and other non-speech-like tracks
Tempo: The overall estimated tempo of a track in beats per minute (BPM). In musical terminology, tempo is the speed or pace of a given piece and derives directly from the average beat duration.
Time signature: An estimated overall time signature of a track. The time signature (meter) is a notational convention to specify how many beats are in each bar (or measure).
Valence: A measure from 0.0 to 1.0 describing the musical positiveness conveyed by a track. Tracks with high valence sound more positive (e.g. happy, cheerful, euphoric), while tracks with low valence sound more negative (e.g. sad, depressed, angry).
Here is the distribution of these metrics for the songs in my library (left) compared to the entirety of Spotify’s database (right). For all graphs shown, the distributions are largely similar suggesting my collection is representative of Spotify’s library.
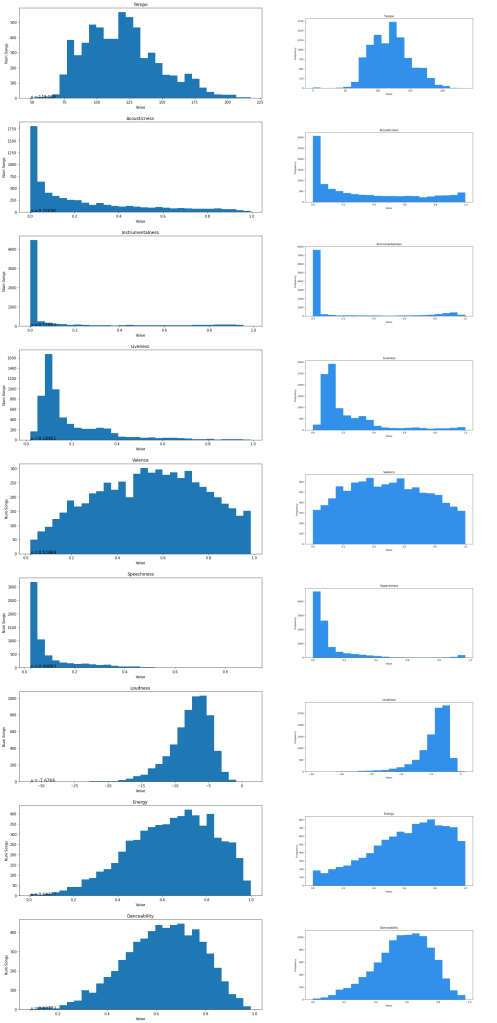
One can rank their playlist by each of these metrics to discover some of the most extreme songs in their library.
Fastest song: The Way We Touch – WE ARE TWIN 218 bpm
Slowest Song: Tennessee Whiskey – Chris Stapleton 49 bpm
Most Acoustic: Avril 14th – Aphex Twin Acousticness: 0.996
Least Acoustic: So Tired – Hockey Dad Acousticness: 0.000001
Bottom ten were all similar Australian punk rock songs, maybe there is something about that genre that results in a low acoustic rating.
I was curious at how well the liveliness metric held up and it turns out it does just alright. In the top ten most “live” songs, 4 of them were actual live recordings. The most live song was not a live recording, Momma Told Me – EARTHGANG (0.989), but just beat out the second most live song Trenchtown Rock – Live At The Lyceum, London/1975 – Bob Marley and the Wailers (0.97)
Valence was another intriguing metric to look at and see how it compared to my own personal opinion. Here are the most “sad” songs in my collection.
| Song | Artist | Valence |
| Sansevieria Green | House | 0.0193 |
| S.T.A.Y. | Hans Zimmer | 0.0250 |
| Nite Rite | STRFKR | 0.0290 |
| Gravity | Synthetic Epiphany | 0.0315 |
| Multicellular | Enrico Sangiuliano | 0.0327 |
| Beach 77 | B77 | 0.0352 |
| L$D | A$AP Rocky | 0.0352 |
| Extreme Northern Lights | Majeure | 0.0353 |
| The Finishing – Original Mix | Stavroz | 0.0363 |
| Annika’s Theme | MATRiXXMAN | 0.0365 |
Most of these are just electronic ambient songs that I wouldn’t necessarily agree stir up any negative emotions (with some exceptions, watch Interstellar to get a good cry), rather, I would say they are devoid of emotion if that makes sense.
On the contrary, I would agree that the top ten most positive songs do fit that billing.
| Song | Artist | Valence |
| Pressure Drop | Toots & The Maytals | 0.985 |
| What a Fool Believes | The Doobie Brothers | 0.985 |
| The Ghost Inside | Broken Bells | 0.983 |
| O Sol (feat. Tita Lima) | The Echocentrics, Tita Lima | 0.981 |
| September | Earth, Wind & Fire | 0.981 |
| Demon’s Cave | Roy Irwin | 0.981 |
| Two Extra Pumps Of Bliss | Enjoy | 0.979 |
| Ryd | Steve Lacy | 0.979 |
| Twist and Shout | Chaka Demus & Pliers, Jack Radics, The Taxi Gang | 0.977 |
| Cocaine Blues | Escort | 0.976 |
Most Energetic:
Satisfaction – Benny Benassi Energy: 0.999
Least Energetic:
Clair de Lune, L. 32 – Claude Debussy,Martin Jones Energy: 0.00532
Danceability was another one of these higher order metrics which I was curious if could hold up.
Top ten most danceable songs according to Spotify:
| Song | Artist | Danceability |
| Poor Relations | Mr Twin Sister | 0.984 |
| Freelance | Toro y Moi | 0.975 |
| Gronlandic Edit | of Montreal | 0.971 |
| Turning Around | Breakbot | 0.966 |
| Shake That | Eminem, Nate Dogg | 0.964 |
| One Night In Bangkok – Single Version | Björn Ulvaeus, Tim Rice, Benny Andersson, Murray | 0.962 |
| So High – Acoustic Version | Rebelution | 0.961 |
| Blow My High (Members Only) | Kendrick Lamar | 0.959 |
| H.S.K.T. | Sylvan Esso | 0.959 |
| Island Girl | Psychic Mirrors | 0.958 |
To my disappointment, the danceability metric performs just alright as well. There are some catchy tunes in the top ten but there are also some WTF instances, most notable being So High by Rebelution. Not a danceable song at all. I was surprised that none of my songs that fall under the actual “dance” genre (besides Toro y Moi) do not appear on the list. It seems like the indie pop/dance genre has more danceability. according to Spotify.
Least Danceable Songs:
| Paw Prints | Tango In The Attic | 0.0883 |
| Clair de Lune, No. 3 | Claude Debussy, Isao Tomita | 0.0942 |
| Varuo | Sigur Ros | 0.12 |
| S.T.A.Y. | Hans Zimmer | 0.12 |
| I ❤ U SO | Cassius | 0.1260 |
| Giant Tortoise | Pond | 0.1330 |
| When I’m With You | Best Coast | 0.1350 |
| 109 | Toro y Moi | 0.1370 |
| Hey Now! | Oasis | 0.1400 |
| I Don’t Wanna Die | Jeff Rosenstock | 0.148 |
Toro y Moi shows up again, guy has so many different sounds and nails all of them.
So there you have it. I hope you learned something today, I know I did while writing this. Now that I am aware of these metrics, I hope to test out some of my own data analysis chops and do some higher order analysis on them in the future, so stay tuned for more!
